python的第11节课笔记(基础高级)
正则的概念
正则表达式:正则表达式由需要匹配的字符和一些特殊字符组成,可以在字符串当中匹配出需要查找的对象
匹配:通过正则表达式快速快捷的匹配出符合要求的特征字符串,比如利用病毒的特征值来查找文本中的病毒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| number = input("请输入一个电话号码:")
if number[0:2] == "13":
print("是一个手机号!!")
else:
pass
import re
num = input("请输入一个手机号:")
r1 = re.findall("^1\d{10}$", num)
print(r1)
r2 = re.findall("^13\d{9}$", num)
print(r2)
|
re模块
1
2
3
4
5
6
7
8
9
10
| re模块 (r"需要获取的数据的正则表达式", 从哪里获取)
re.findall() 匹配整个字符串
存在则以列表形式返回
不存在返回空列表
re.match() 只匹配开头,从头开始一一对照比较
存在则返回对象,需要使用对象.group() 查看到具体匹配的字符
不存在则返回 None
re.search() 匹配整个字符串
存在则返回对象
不存在则返回 None
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import re
st = "This is cls15 2023.05.19 LiuMu 18"
print(re.findall(r"i", st))
print(re.findall(r"this", st))
print(re.match(r"i", st))
res1 = re.match(r"T", st)
print(res1.span())
print(res1.group())
res2 = re.match(r"This", st)
print(res2.span())
print(res2.group())
print(re.match(r"THis", st))
res3 = re.search(r"is", st)
res3 = re.search(r"i", st)
print(res3.group())
print(res3.span())
print(re.search(r"a", st))
|
操作字符串
1
2
3
4
5
6
7
8
9
10
11
12
| 操作字符串
字符串方法
replace() 替换
split() 切割
find()
re.sub(旧, 新, 操作的数据, [限制次数])
默认修改所有
如果指定,则从前面顺序修改
re.split("[字符1字符2字符3]") 可以同时指定多种切割方式
注意:如果存在元字符,一定要\取消转义
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import re
st = "This is cls15 2023.05.19 LiuMu 18"
st1 = st.replace("is", "IS")
print(st1)
st2 = st.split("i")
print(st2)
print(st.find("i"))
修改
res4 = re.sub("c", "C", st)
res4 = re.sub("i", "I", st, 2)
print(res4)
切割
需求:将里面空格隔开的字符串切割出来,并且年月日的数字也要切割出来
st4 = st.split(" ")
st5 = st4[3].split(".")
print(st5)
注意:re里面的.是一个元字符,具有特殊含义,需要在前面加上反斜杠附小特殊功能
res5 = re.split("[ \.]", st)
print(res5)
res6 = re.split()
提前编译正则格式
s = re.compile(r"\d")
res6 = re.findall(s, st)
print(res6)
|
元字符
正则表达之所以能够快速匹配字符串,是因为其有非常多的元字符,和我们字符串的转义有点类似,这些元字符代表了那些含义呢
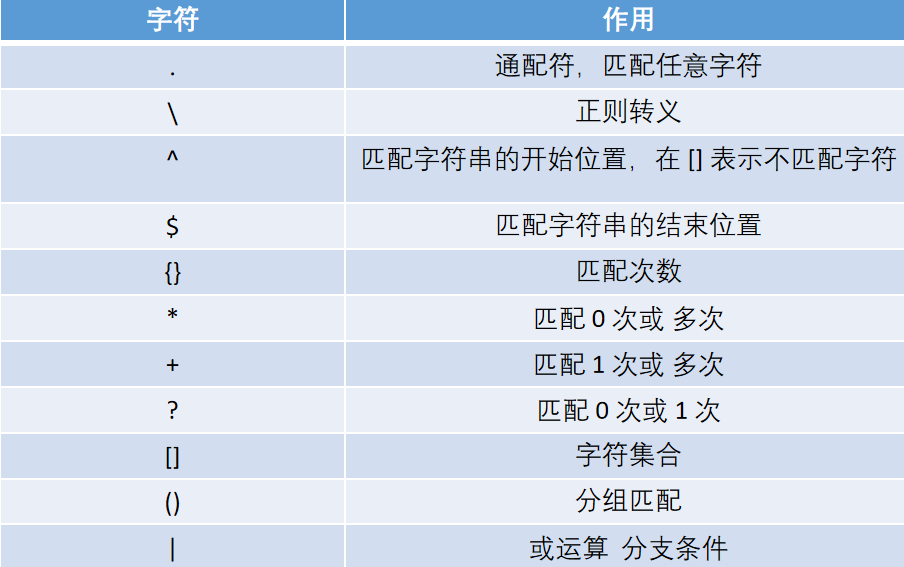
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| """
num = input("请输入一个手机号:")
# ^1 匹配1开头 {10}:匹配10次,原因:除了1之外,还有10个数
r1 = re.findall("^1\d{10}$", num)
print(r1)
# ^13 匹配13开头的
r2 = re.findall("^13\d{9}$", num)
print(r2)
"""
import re
"""
单词边界
\b(字符串两端不是正规字符,就会认为是单词边界)
正规字符: 数字、字母、下划线、中文
cemos$¥¥¥@yfa
总结:
1、正规字符
2、有空格
"""
"""
特殊字符
\d 匹配数字
\D 匹配数字之外的
\s 匹配空白字符(空字符)、空格、制表符、换行符
\. 匹配点本身
"""
"""
匹配次数
* 随意次数 {0,}
+ 至少一次 {1,}
? 最多一次
{最少次数,最大次数} 双闭区间
{a} 默认是最大次数
{a,} 最大次数为无穷大
{,a} 默认最小次数为0
默认贪婪模式,按最大限度拿取,不够了再取剩下的小的
"""
"""
贪婪模式与非贪婪模式
"""
"""
集合
[A-Z] 匹配所有英文字母大写
[a-z] 匹配所有英文字母小写
"""
"""
分组匹配
() 表示分组, 默认是保留括号内匹配上的内容
只匹配括号里面,外面不会匹配
"""
st = '''
<a class="m_on" href="//www.4399.com/">首页</a>
<a href="/flash_fl/2_1.htm">动作</a>
<a href="/flash_fl/3_1.htm">体育</a>
<a href="/flash_fl/5_1.htm">益智</a>
<a href="/flash_fl/4_1.htm">射击</a>
<a href="/flash_fl/6_1.htm">冒险</a>
<a href="/flash_fl/7_1.htm">棋牌</a>
<a href="/flash_fl/8_1.htm">策略</a>
<a href="/flash_fl/12_1.htm">休闲</a>
<a href="/special/195.htm">女生</a>
<a href="/flash_fl/16_1.htm">装扮</a>
<a href="/flash_fl/13_1.htm">儿童</a>
<a href="/special/90.htm">过关</a>
<a href="/special/1.htm">双人</a>
<a class="gp" href="//www.4399dmw.com/donghua/">动画片</a>
<a class="gp" href="//www.3000.com/">闪艺互动</a>
<a class="gp" href="//www.4399.cn/">手机游戏</a>
'''
print(re.findall(r'<a href="/special/1.htm">.*?</a>', st))
print(re.findall(r'<a href="/special/1.htm">(.*?)</a>', st))
print(re.findall(r'>.*?<', st))
print(re.findall(r'>(.*?)<', st))
|