python的第二节课笔记(基础入门)
| python共有六大基础数据类型:分别是数值,字符串,列表,元组,字典,集合。 |
数值:
常见数值类型:
| int | 整型 ( 没有小数点) |
|---|---|
| float | 浮点型 (小数,有小数点) |
| bool | 布尔类型 ( True False) [首字母必须大写] |
常用函数:
| 语法 | 解释 |
|---|---|
| type(数据) | 查询数据的类型 |
| id(变量) | 查询变量的内存地址 |
示例:
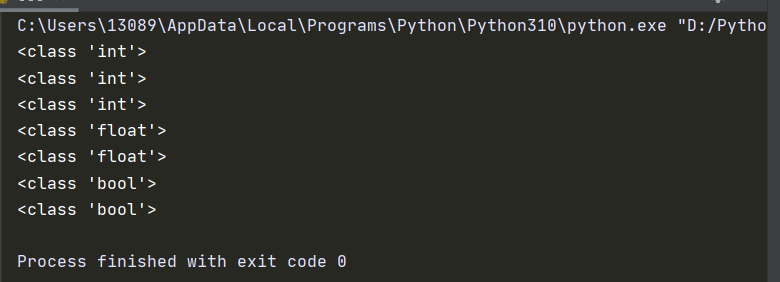
1 | print(type(1)) |
1 | a = 100 |
运行结果为:

常见运算符
| 符号 | 意义 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| // | 取整 |
| % | 取余 |
| ** | 次方/幂 |
注意:
- 在python中bool型的True和False分别等同于1和0,也可直接进行运算
- 数值类型是不可变(更改之后,内存地址也会发生改变,没有增删改查等操作)的非序列结构(存储的只能为单个元素,不可进行拆分,没有下标索引的概念),即用变量接收一个数值,只能为一个地址,一种数据类型
- 上面是常见数值类型 ,数值是不可变的数据类型
示例:
1 | # 1、创建了两个变量 |
数据类型强转:
| 语法 | 解释 |
|---|---|
| int(想要转变的数据) | 强转为整型 |
| float(想要转变的数据) | 强转为浮点型 |
| str(想要转变的数据) | 强转为字符串 |
数值模块(了解):
注意:
- 只要运算双方有一个浮点型的存在,结果必然是浮点型
- 浮点数无法作高精度计算,原因:计算机的底层都是二进制,浮点数存在精度问题们无法完全转变为二进制
- 解决:导入decimal模块
- 作用:1、提高计算的精密度 2、可以用作字符串包裹的数值的计算
1 | import decimal |
运行结果为:

字符串:
字符串的定义:
| 生活当中遇到的文本信息就是字符串,只要在键盘上能够打出来的字符都是字符串,使用str表示。 |
总的来说,字符串可以有三种定义方式,分别是:单引号、和双引号三引号(三个单引号和三个双引号),只有三引号才支持换行,其他两种不支持换行
1 | st1 = '这是第二个字符串' |
字符串的特点:
| 不可变的有序序列结构。 |
注意:
- 不可变:有增删改查的操作,生成的数据需要使用新变量接收
- 序列:可以存储多个元素,可以进行拆分有下标索引的概念
- 序列结构的数据类型有:字符串,列表,元组
字符串的查找:
| 查找单个值 | 形式为 索引(下标),即 str[下标] |
|---|---|
| 查找多个值 | 即切片,形式为 str[起始下标:结束下标] |
| 隔位取值 | 形式为 str[起始:结束:步长] |
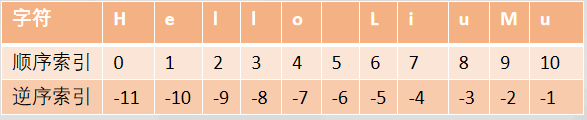
注意:
- 顺序:索引从0开始
逆序:索引从-1开始 - 查找多个值时,区间为左闭右开区间,因此实际操作,结束下标需要+1位
- 起始下标默认为第一个, 结束下标默认为最后一个
- 步长默认为1, 想要隔n位取,就步长设置为 n+1
顺序,步长没有要求,负数表示取反
逆序,步长为负
1 | str1 = "你们好呀,15期的小伙伴!" |
字符串的拼接:
| 方法数 | 解释 | 语法 |
|---|---|---|
| 法一 | +表示直接拼接 | str + str |
| 法二 | * 表示成倍复制 | str * int |
| 法三 | 利用字符串的格式化来拼接字符串 | 语法1:”%s %f”%(str, float) |
| 法四 | 利用format方法来拼接 | 语法1: “{}{}”.format(变量1,变量2) 语法2:f”{变量1}{变量2}” |
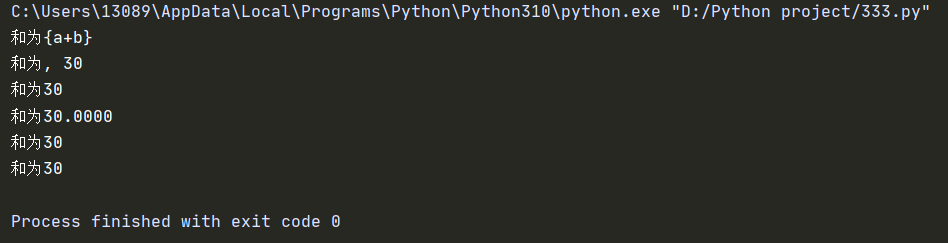
1 | # 法一法二 |
1 | # 法三法四 |
运行结果为:
字符串格式化:
| 解释 | 语法 | |
|---|---|---|
| 法一 | 字符串的 %r 和 %s,%f 格式化输出 | “%.2f”%变量名 |
| 法二 | 字符串的 format 方法 | “{}”.format(变量名) f”{变量名}” |
| 法三 | join方法 | “链接符号”.join(序列) |
| %s | 转化为字符串 |
|---|---|
| %f | 转化为浮点型,其中%.nf,保留n位小数 |
| %d | 格式化为整数 |
| %r | 原样输出 |

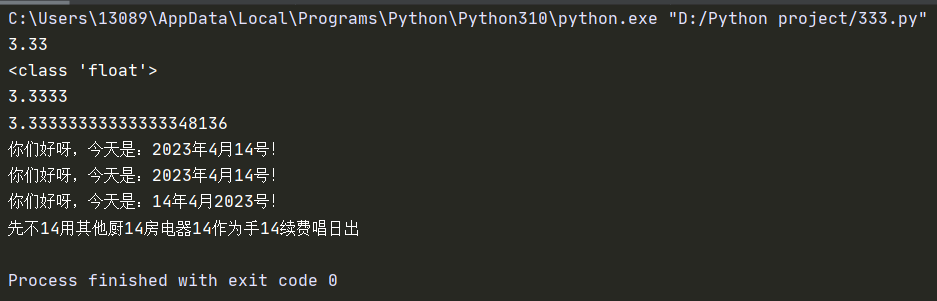
1 | lm = 3.3333333333333333 |
运行结果为:
错误示范:
1 | year = 2023 |
运行结果为:

法三:
1 | """ |
常见疑问:
print(f"第{week}周,第{day}天")这句话的f和{week}分别代表什么?
这句话中的 f 是 Python 3.6 中引入的 f-string(格式化字符串)语法,可以方便地将变量的值插入到字符串中,而不需要使用传统的字符串格式化方法。
在 f-string 中,用 {} 包围的变量会被替换成对应的值。例如,{week} 会被替换成 week 变量的值。通过在 {} 中使用表达式,可以进行更复杂的字符串格式化操作。
例如,在下面的例子中,我们可以使用 f-string 将数字变量插入到字符串中:
1 | # 定义变量 |
在上面的例子中,我们使用 f-string 将变量 x 和 y 插入到字符串中,并且在字符串中直接使用了这些变量的值。
总之,f 是 f-string 的开头,而 {week} 是表示要插入 week 变量的值。
字符串的更改:
| 字符串不可变,需要使用新变量接收。 |
| 语法 | 解释 |
|---|---|
| str.replace(旧,新) | 默认更改所有 |
| str.replace(旧,新,次数) | 顺序更改指定次数 |
1 | str1 = "hello ah tongxue!" |
字符串切割:
| 语法 | 解释 |
|---|---|
| str.split(“指定分割字符”) | 从指定字符处分割,默认指定分割字符有几个,就分割几次 |
| str.split(“指定分割字符”,次数) | 从指定字符处分割,可指定分割次数 |
1 | str2 = "20230414" |
运行结果为:

字符串查找:
| 语法 | 解释 |
|---|---|
| str.find(“指定查找字符”) | 从整个字符串查找 |
| str.find(“指定查找字符”,起始,结束) | 从指定位置查找 |
注意:
- 找到:返回字符的下标
- 没有找到:返回-1
1 | str1 = "hello ah tongxue!" |
首字母转变大写:
| 语法 | 解释 |
|---|---|
| str1.title() | 字符串首字母转变大写 |
1 | str1 = "beautiful" |
字符串的其他方法:

字符串转义:
| 在特定字符前面加 \ 会解释成带有特殊含义的转义字符(在print内起作用)。 |
注意:
- \n:换行
- \t :水平制表符—默认以8个字符长度对齐,超过则按8的倍数对齐
- 在转义字符前面再加一个\可以取消转义,同时在字符串前面加r可以取消字符串内所有转义字符
1 | print("hellocls15sky") |
运行结果为:
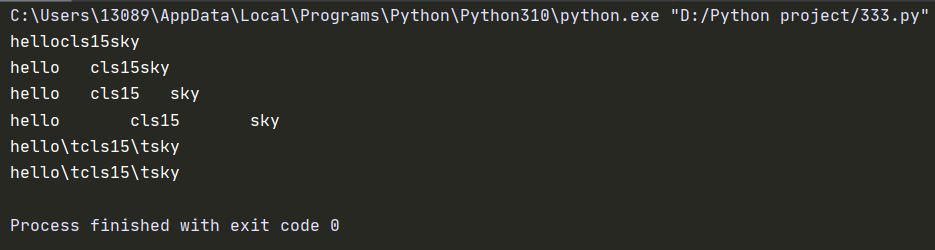
字符串的编码:
| 字符串编码是为了在计算机中表示和处理文本数据。计算机内部以二进制形式存储和处理数据,而文本是由字符组成的,每个字符都有一个对应的编码值。因此,为了在计算机中表示和处理文本,需要将字符映射到对应的编码值。 |
| str.encode(“编码方式”) | 默认以utf-8格式编码,当然可以指定encoding编码格式。 |
|---|---|
| str.decode(“解码方式”) | 解码,和encode用法一致 |
注意:
- 用什么编码就用什么解码,否则会乱码
1 | jk = "酒空" |
运行结果为:
